Monitorer ses logs avec Logstash
Lundi matin, aux environs de 9 h 30. Vous arrivez un peu en retard, mais bon c’était pour la bonne cause, il fallait impérativement finir de merger ces pull requests sur votre projet perso et vous en avez eu jusqu’à 3h du mat’. Même pas le temps d’aller prendre une boisson chaude pour se réveiller, le téléphone sonne : une anomalie ultra-bloquante-qui-va-mettre-en-péril-le-projet-c’est-pas-possible vient d’être ouverte, c’est la catastrophe bla bla bla… Classique, me direz-vous, mais comment trouver facilement l’origine du problème ?
Les logs, bien sûr !
Comme d’habitude, le ticket a été ouvert à l’arrache, il va falloir batailler ne serait-ce que pour avoir une heure approximative à laquelle le problème s’est produit. Vous vous connectez en SSH sur la machine de prod, lancez un vim + /var/log/jboss/server.log et c’est parti pour la recherche ! Ah, en fait il y a eu plein de stacktraces depuis minuit, c’est dingue ça… et évidemment, c’est pas très lisible. Bon, depuis combien de temps le problème existe ? Il va falloir faire un grep sur tous les logs pour voir si l’erreur a déjà été rencontrée auparavant. Et puis tant qu’à faire, autant jeter un œil à toutes ces autres erreurs qu’on a trouvées par hasard…
Un analyseur de logs à la rescousse
Mieux vaut prévenir que guérir1 . L’idéal serait d’avoir un outil qui scrute automatiquement les logs à la recherche de WARN et d’ERROR. Il existe pas mal d’outils dans ce genre, comme quoi le problème est bien reconnu et adressé : Stack Hunter2, Baretail ou encore Logstash. Dans cet article, je vais vous présenter Logstash, car il est gratuit, open source et multiplateforme (et parce qu’il faut bien faire un choix, après tout).
Mais que ce soit Logstash ou un autre, les principes généraux restent les mêmes. À partir de fichiers de logs, l’outil va découper chaque évènement en plusieurs champs (date, sévérité, origine, message, …), stocker les évènements et proposer une interface permettant de les visualiser et de les requêter de manière efficace. Les outils les plus avancés sauront même vous envoyer un SMS, un courriel ou faire miauler votre chat en morse pour vous avertir d’un nouveau problème !
Ship logs from any source, parse them, get the right timestamp, index them, and search them.
Installation et utilisation de Logstash
L’installation de Logstash est simple comme hello world. Il suffit de récupérer l’archive de la dernière version sur le site officiel, de l’extraire et voilà ! En regardant rapidement le contenu extrait, on remarque que l’application est faite en Ruby (avec un JRuby pour l’exécuter), et qu’elle embarque Elasticsearch et Kibana avec elle.
Comme l’indique le tutoriel, la manière la plus simple d’utiliser Logstash est la suivante :
bin/logstash -e 'input { stdin { } } output { stdout {} }'Le flag -e permet de spécifier la configuration dans la ligne de commande : les données en entrée seront prises dans stdin, et le résultat sera envoyé vers stdout. En tapant un message dans la console, Logstash réagit immédiatement :
hello world
2013-11-21T01:22:14.405+0000 0.0.0.0 hello worldL’évènement généré se découpe en 3 champs : une date, une IP d’origine et un message.
OK pour le hello world, maintenant il faut gérer un cas plus complexe, à savoir des logs serveur ayant une forme ressemblant à ceci :
2015-03-16 13:37:42 ERROR prod.acme.com - p.t.d.r.MyClass - Une erreur est survenue, bla bla bla administrateur bla bla réessayer dans quelques minutesEt puis tant qu’à faire, on voudrait bien stocker les évènements parsés pour pouvoir les requêter par la suite. C’est le moment de vous expliquer comment fonctionne la configuration de Logstash. Le traitement d’un évènement se divise en plusieurs phase : les Inputs, les Filters, les Outputs et les Codecs. La configuration simpliste de tout à l’heure (input { stdin { } } output { stdout {} }) ne contenait qu’un input et un output. Au lieu de stdout, nous voulons stocker (output) les données dans une base Elasticearch. Au lieu d’un simple message, nous voulons parser (filter) des logs serveur (input). La configuration ressemblerait alors à ceci :
input {
file {
type => "myServerLogs"
path => ["/var/log/jboss/server.log"]
}
}
filter {
grok {
match => [ "message", "%{TIME:logtime}%{SPACE}%{LOGLEVEL:rawlevel}%{SPACE}%{DATA:machine}%{SPACE}-%{SPACE}%{JAVACLASS:class}%{SPACE}-%{SPACE}%{GREEDYDATA:message}" ]
}
date {
match => [ "timestamp" , "yyyy-MM-dd HH:mm:ss" ]
}
}
output {
elasticsearch {
embedded => true
}
}L’entrée est donc un fichier, et la sortie une base Elasticsearch embarquée. Le filtre utilise le plugin grok qui permet de structurer un texte quelconque. On lui indique que chaque message est formatté selon les placeholders indiqués, et grok va découper chaque ligne de cette manière.
La commande à lancer change en bin/logstash -f myConf.conf web. On demande à Logstash d’utiliser un fichier de configuration nommé myConf.conf et de lancer un serveur web pour visualiser le résultat. Une fois l’appli lancée, si on ajoute quelques lignes dans le fichier server.log, Logstash devrait les prendre en compte. Pour le vérifier, connectons-nous à l’adresse http://localhost:9292/. Miracle, une belle interface apparait. Il s’agit de Kibana, une interface de visualisation de données stockées dans une base Elasticseach (le monde est bien fait, hein). Kibana ne sait pas trop quoi faire, alors il nous propose plusieurs manières de configurer nous-même un dashboard répondant à nos attentes. Pour cela, nous allons cliquer sur le lien “Sample Dashboard - I don’t have much data yet, please extract some basics for me”, qui nous redirige vers un dashboard ultra générique :
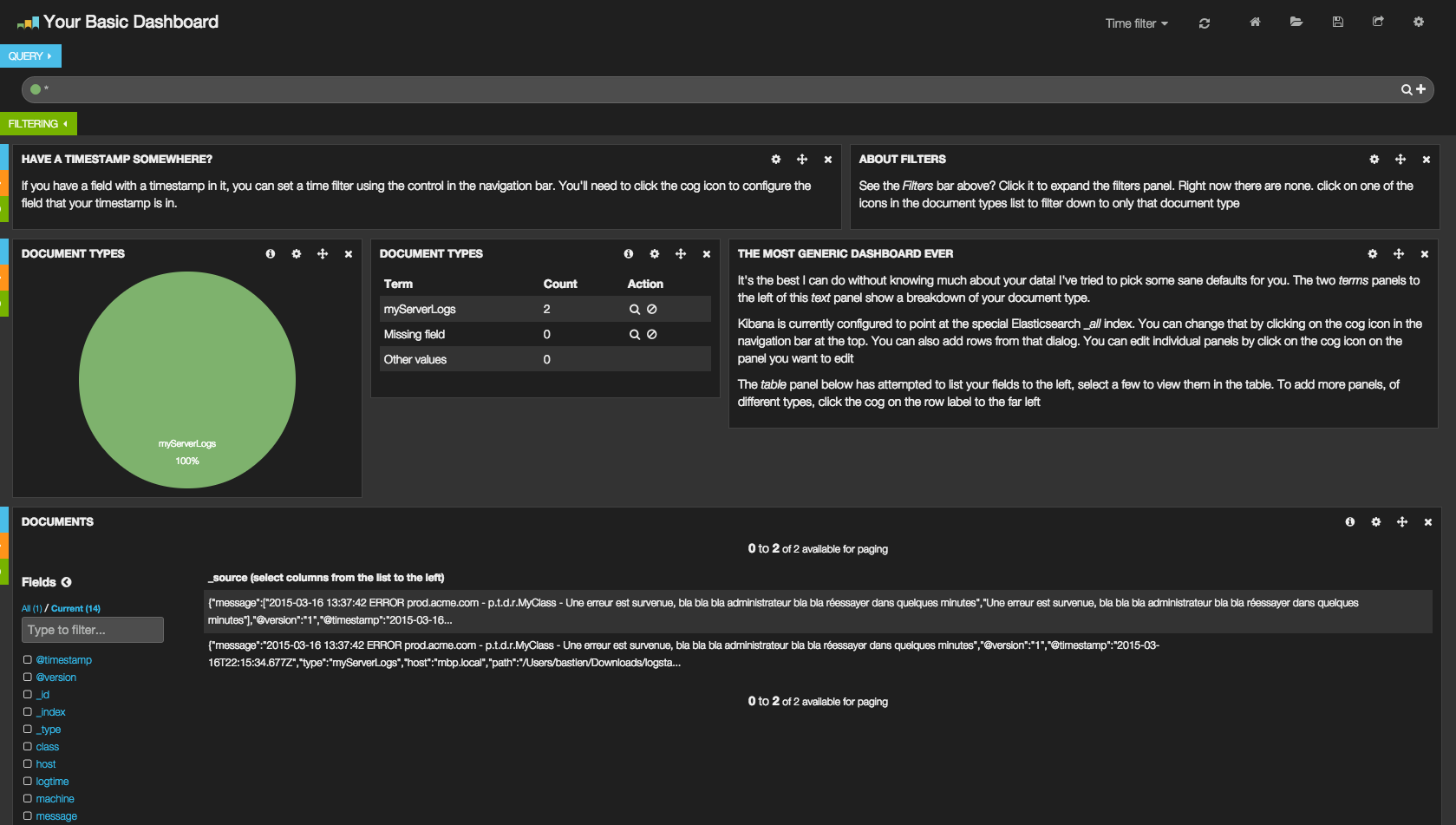
La partie query permet de requêter les évènements, par exemple rawlevel:ERROR pour filtrer les logs ERROR. La partie filtering permet de filtrer les évènements affichés (semblable aux queries, mais appliqué tout le temps). De beaux graphiques permettent de visualiser rapidement les informations importantes (ici, la provenance des logs). Enfin, la partie basse liste les évènements. En cliquant sur une ligne, un tableau détaille chaque champ et sa valeur, ce qui confirme que nos logs ont bien été parsés :
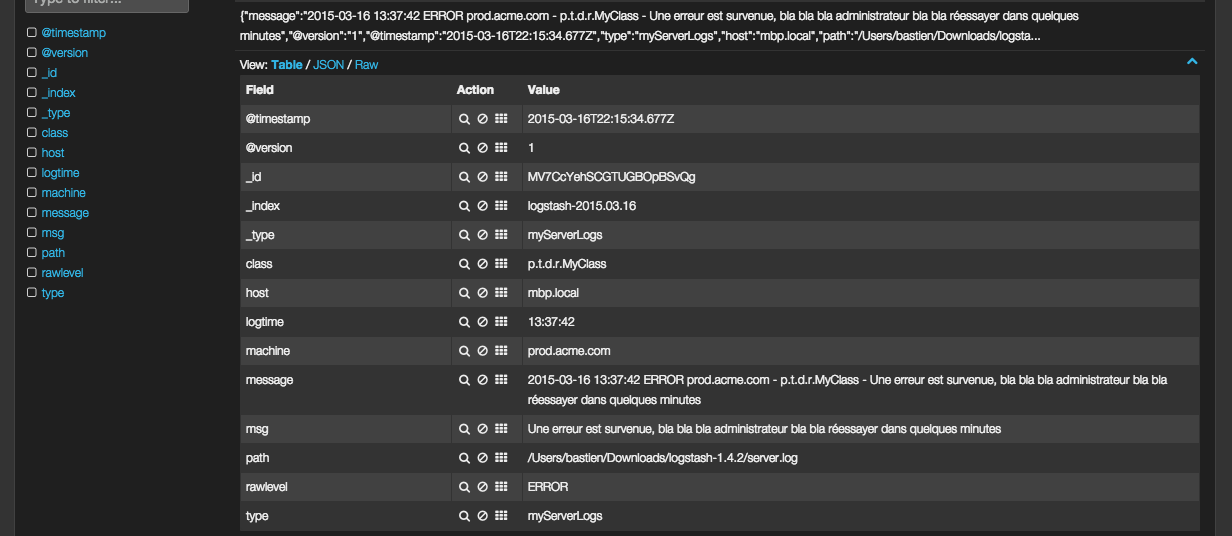
Je vous laisse le soin de fouiner dans les possibilités offertes par Kibana, les dashboards seront très différent d’un projet à l’autre selon les besoins. Une recherche Google montre que l’on peut faire de très jolies choses (autant joindre l’utile à l’agréable).
J’aime pas parser les logs !
Tout ça est bien beau, mais en général les erreurs de nos chères applications Java sont accompagnées de leur fidèles sidekicks, les stack traces. Et comme on ne peut plus se passer de proxies Spring, de filtres et de toutes ces choses qui s’ajoutent à la pile d’appels, celle-ci tend à devenir gigantesque. Par conséquent, un seul évènement de log va se répercuter sur plusieurs lignes, qu’il va falloir agréger pour qu’on s’y retrouve dans Kibana. Plusieurs solutions s’offrent à nous :
- utiliser le codec multiline en complément de grok pour agréger les lignes
- faire en sorte de ne plus avoir à parser les fichiers de logs en intervenant en amont
- ??
- la réponse d)
Je vous avoue que j’ai testé la première solution sans vraiment y arriver. Du coup, je me suis dit que la seconde solution serait intéressante si on avait la possibilité de se brancher directement sur SLF4J (comment ça, vous utilisez Log4J directement ?) pour envoyer les évènements à Elasticsearch sans passer par la case parsing.
C’est le moment d’appeler logstash-logback-encoder à la rescousse. Cet appender pour Logback permet d’encoder les messages loggués en JSON, puis d’envoyer le tout via une socket TCP à Logstash. Comme vous pouvez l’imaginer, le contenu JSON est directement structuré comme il faut, plus besoin de parser avec des regex, d’agréger des lignes, etc. Après avoir récupéré la bonne dépendance, la configuration du logback.xml est très simple :
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="stash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>WARN</level>
</filter>
<host>127.0.0.1</host>
<port>4560</port>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
<appender-ref ref="stash" />
</root>
</configuration>Nous avons donc défini un appender basé sur une socket TCP, qui envoie les évènements sur 127.0.0.1:4560. L’encoder permet de sérialiser les données au format JSON. Notez que le niveau de logs par défaut est DEBUG, mais qu’il est possible de le restreindre par exemple à WARN en utilisant un ThresholdFilter, puisque nous ne sommes intéressés que par les WARN/ERROR. L’appender STDOUT continuera de logguer les niveaux >= DEBUG.
Côté Logstash, pour pouvoir recevoir correctement les évènements, on configure une entrée TCP, encodée en JSON, sur le port adéquat :
input {
tcp {
port => 4560
codec => json
}
}Après redémarrage de Logstash, les évènements sont loggués comme prévu. Il est à noter que l’appender est asynchrone (LMAX Disruptor RingBuffer inside), il ne bloquera jamais le thread qui génère les logs. En cas de problème réseau, l’appender peut se reconnecter à Logstash. Si le buffer est plein, certains évènements peuvent toutefois être perdus.
Conclusion
J’espère que cet article vous a donné envie de tester Logstash sur votre projet. Comme vous avez pu le remarquer, la configuration est relativement simple lorsqu’il s’agit d’indexer les erreurs et stacktraces. Je n’ai volontairement pas compliqué les choses, mais sachez qu’il est possible de faire des choses relativements complexes aussi bien dans l’indexation des logs que dans les dashboards côté Kibana (largement de quoi s’adapter à votre configuration et vos besoins). De plus, Logstash est capable de parser tout et n’importe quoi, il propose par défaut une série de patterns permettant de parser des dates, des logs Apache, Syslog, Nagios, MongoDB etc.
Pour aller plus loin
-
Il parait que les allemands disent “La prévention est la mère de la caisse à porcelaine” ↩
-
Rien à voir avec mon projet perso, qui fait la même chose mais qui n’est pas aussi abouti ↩